I’ve been catching up on the topic of memory management for AI agents recently and was overwhelmed by the amount of new terminology and concepts. This blog post serves as my working study notes to collect all the information on memory for agents. Therefore, please note that this information is subject to change as I’m learning more about the topic (refer to the last modified date on this post).
What is agent memory?
Memory in AI agents is the ability to remember and recall important information across multiple user interactions. This ability enables agents to learn from feedback and adapt to user preferences, thereby enhancing the system’s performance and improving the user experience.
Large Language Models (LLMs) that power AI agents are stateless and don’t have memory as a built-in feature. LLMs learn and remember information during their training phase and store it in their model weights (parametric knowledge), but they don’t immediately learn and remember what you just said. Therefore, every time you interact with an LLM, each time is essentially a fresh start. The LLM has no memory of previous inputs.

Therefore, to enable an LLM agent to recall what was said earlier in this conversation or in a previous session, developers must provide it with access to past interactions from the current and past conversations.
The term “memory”
I still struggle with the new terminology surrounding this topic. I like the definition for (human) memory on Wikipedia, which says, “Memory is the faculty of the mind by which data or information is encoded, stored, and retrieved when needed”.
That means “memory” refers to the storage location (e.g., a Markdown file or a database), and the actual information stored is not called “memories,” but rather “information.”
Difference between agent memory and agentic memory
When I first started researching the topic of agent memory, I thought “agent memory” or “memory for agents” was the same as “agentic memory”. Turns out (or rather: I think), they are not, but they are related:
- Agent memory (or memory for agents) refers to the concept of granting agents access to memory, allowing them to recall information from past interactions.
- Agentic memory describes a memory system that agentically writes and manages memory for agents (usually via tool calls).
That means, “agentic memory” always refers to “agentic memory for agents,” but “agent memory” doesn’t necessarily have to be agentic. (Curious if my understanding is correct on this.)
Types of agent memory
Agent memory can be categorized into different types depending on the type of information stored and its location. There are various ways to categorize agent memory into distinct types. But at the highest level, they all differentiate between short-term (in-context) and long-term memory (out-of-context):
- In-context memory (Short-term memory) refers to the information available in the context window of the LLM. This can be both information from the current conversation as well as information pulled in from past conversations.
- Out-of-context memory (Long-term memory) refers to the information stored in external storage, such as a (vector or graph) database.
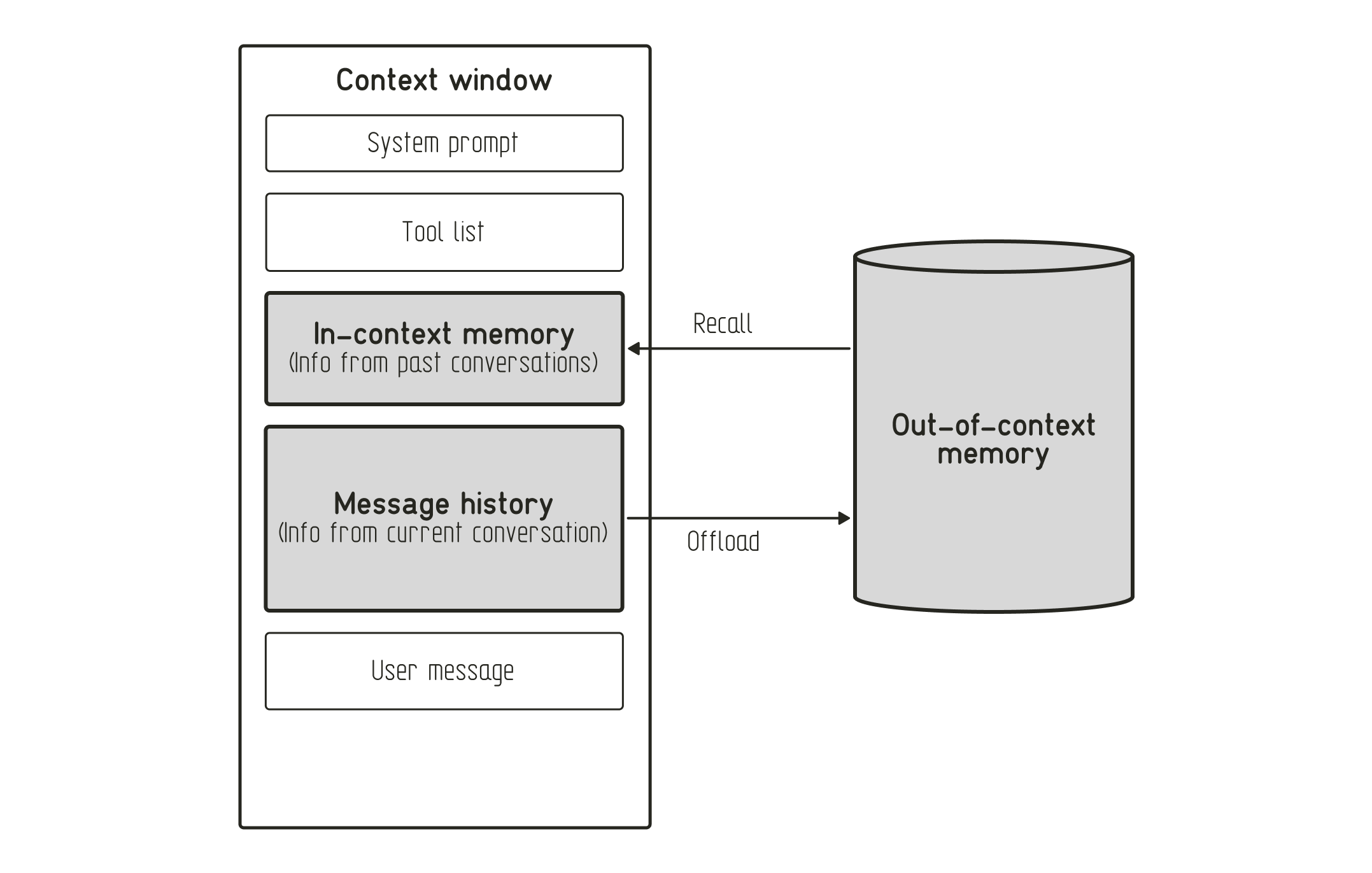
The most commonly seen topology is based on the Cognitive Architectures for Language Agents (CoALA) paper, which distinguishes between four memory types that mimic human memory, drawing on the SOAR architecture from the 1980s. Below, you can find a table of the different memory types inspired by a similar one in the LangGraph documentation:
| Memory Type | What is stored | Human Example | Agent Example |
|---|---|---|---|
| Working memory | Contents of the context window | Current conversation (e.g., “Hi, my name is Sam.”) | Current conversation (e.g., “Hi, my name is Sam.”) |
| Semantic memory | Facts | Things I learned in school (e.g., “Water freezes at 0°C”) | Facts about a user (e.g., “Dog’s name is Henry”) |
| Episodic memory | Experiences | Things I did (e.g., “Went to Six Flags on 10th birthday”) | Past actions (e.g., “Failed to calculate 1+1 without using a calculator”) |
| Procedural memory | Instructions | Instincts or motor skills (e.g., “How to ride a bike”) | Instructions in the system prompt (e.g., “Always ask follow-up questions before answering a question.”) |
However, there’s also another approach to categorizing memory types for AI agents from a design pattern perspective. Sarah Wooders from Letta argues that an LLM is a tokens-in-tokens-out function, not a brain, and that, therefore, the overly anthropomorphized analogies are not fit. If you look at how Letta defines the types of agent memory, you will see that they define it differently:
- Message Buffer (Recent messages) stores the most recent messages from the current conversation.
- Core Memory (In-Context Memory Blocks) is specific information that the agent itself manages (e.g., the user’s birthday or the boyfriend’s name if this is relevant to the current conversation)
- Recall Memory (Conversational History) is the raw conversation history.
- Archival Memory (Explicitly Stored Knowledge) is explicitly formulated information stored in an external database.
The difference lies in how they design in-context and out-of-context memory. For example, CoALA’s working memory is one category, while Letta splits this into message buffer and core memory. The long-term memory from the CoALA paper can be thought of as the out-of-context memory in Letta. However, the long-term memory types of procedural, episodic, and semantic aren’t directly mappable to Letta’s recall and archival memory. You can think of CoALA’s semantic memory as Letta’s archival memory, but the other are different from each other. Notably, the CoALA taxonomy doesn’t include the raw conversation history in long-term memory.
AI Agent Memory Management
Memory management in AI agents refers to how to manage information within the LLM’s context window and in external storage, as well as how to transfer information between them. Richmond Alake lists the following core components of agent memory management: generation, storage, retrieval, integration, updating, and deletion (forgetting).
Managing memory in the context window
The goal of managing memory in the context window is to ensure that only relevant information is retained, thereby avoiding confusion for the LLM with incorrect, irrelevant, or contradictory information. Additionally, as the conversation progresses, the conversation history grows (involving more tokens) and leads to slower responses and higher costs, potentially reaching the context window’s limit.
To mitigate this problem, you can maintain the conversation history in different ways. For example, you can manually remove old and obsolete information from the context window. Alternatively, you can periodically summarize the previous conversation and retain only the summary, then delete the old messages.
Managing memory in external storage
The main goal of memory management in external storage is to prevent memory bloat and to ensure the quality and relevance of the stored information. The four core operations for managing memory in external storage include:
- ADD: Adding new information to the external storage.
- UPDATE: Identifying existing information, modifying it to reflect new information, or correcting outdated information (e.g., updating a user’s new address).
- DELETE: Forgetting obsolete information to prevent memory bloat and degradation of the information quality.
- NOOP: This is the decision point where the memory management system determines that the current interaction contains no new, relevant, or contradictory information that warrants a database transaction.
Transferring information between the context window and external storage
One important question developers need to answer is when to manage memory, specifically when to transfer information from the context window to external storage. The LangChain blog post on “memory for agents” differentiates between the hot path and background, while I’ve also seen the two referred to as explicit and implicit memory updates in Philipp Schmid’s blog on “Memory in Agents”.
Explicit memory (hot path) describes the agent memory system’s ability to autonomously recognize important information and decide to explicitly remember it (via tool calling). Explicit memory in humans is the conscious storage of information (e.g., episodic and semantic memory). While ideally, remembering important information in the hot path is how humans remember information, it can be challenging to implement a robust solution that understands which information is important to remember.
Implicit memory (background) describes when memory management is programmatically defined in the system at specific times during or after a conversation. Implicit memory in humans is the unconscious storage of information (e.g., procedural memory). The Google whitepaper on session and memory describes the following three scenarios:
- After a session: You can batch process the entire conversation after a session.
- In periodic intervals: If your use case has long-running conversations, you can define an interval at which session data is transferred to long-term memory.
- After every turn: If your use case has requirements for real-time updates. However, keep in mind that the raw conversation history is typically appended and stored in the context window for a short period (“short-term memory”).
Implementing agent memory
When implementing agent memory, consider where to store the memory information:
- Current conversation history is usually implemented as a simple list of past user queries, assistant messages, and maybe tool calls or reasoning.
- Instructions are typically found in text or Markdown files, similar to well-known examples such as CLAUDE.md files.
- Other information is usually stored in a database, depending on what type of retrieval method is suitable for your data.
If you’re interested in actual code implementation, I recommend you check out how my colleague JP Hwang implemented an agentic memory layer for a conversational AI using Weaviate or how Adam Łucek implements the four different types of memory from the CoALA paper (working memory, episodic memory, semantic memory, and procedural memory).
Challenges of agent memory design
Implementing memory for agents currently is a challenging task. The difficulty lies in optimizing the system to avoid slower response times while simultaneously solving the complex problem of determining what information is obsolete and should be permanently deleted:
- Latency: Constantly processing whether the agent now needs to retrieve new information from or offload data to the memory bank can lead to slower response times.
- Forgetting: This seems to be the hardest challenge for developers at the moment. How do you automate a mechanism that decides when and what information to permanently delete? Managing the information stored in external memory is important to avoid memory bloat and the degradation of the information quality.
Frameworks for AI Agent Memory
The ecosystem of developer tools for implementing memory solutions for agents is rapidly growing and attracting investors’ attention. There are frameworks dedicated to solving the agent memory problem, such as:
- mem0 (see my example implementation with Weaviate),
- Letta based on the MemGPT design pattern (see my example implementation),
- Cognee, and
- zep.
However, many agent orchestration frameworks, such as:
- LangChain and LangGraph,
- LlamaIndex (see my example implementation),
- CrewAI, and
- Google’s Agent Development Kit (ADK) (see my example implementation),
also offer solutions for AI agent memory management. Additionally, some model provider’s such as Anthropic, provide built-in memory tools (see my example implementation).
Summary
As I’m diving into the topic of memory management for AI agents, I’m learning the importance of not only remembering information from the current conversation but also past conversations, and also how to modify and forget outdated and obsolete information effectively.
As the field evolves, different approaches and terminology are emerging with it. On the one hand, you have approaches that categorize memory types into semantic, episodic, or procedural memory, analogous to the human memory. On the other hand, you have approaches, such as Letta, which use architecture-focused terminology.
Nevertheless, the core challenge of memory design for AI agents is how to flow information between an LLM’s context window (short-term memory) and external storage (long-term memory). This involves deciding when to manage updates (hot path vs. background) while overcoming key challenges such as latency and the difficulty of forgetting obsolete data.